In this post, I will try to address a common misunderstanding about the difficulty of training deep neural networks. It seems to be a widely held belief that this difficulty is mainly, if not completely, due to the vanishing (and/or exploding) gradients problem. “Vanishing gradients” refers to the gradient norms becoming exponentially smaller for parameters deeper in the network. Smaller gradients mean parameters changing ever so slowly, and so learning gets stuck until the gradients become large enough, which could take exponentially long. This idea goes back, at least, to Bengio et al. (1994) and still seems to be everybody’s favorite explanation for why it is hard to train deep neural networks.
Let’s first consider a simple scenario: a deep linear network being trained to learn a linear mapping. Of course, deep linear networks aren’t interesting from a computational perspective, but Saxe et al. (2013) showed that learning dynamics in such networks can still be informative about the learning dynamics in nonlinear networks. So, let’s start with this simple scenario. Here’s the learning curve and the initial gradient norms (before any training) for a 30-layer network (errorbars are standard errors over 10 independent runs).

I will shortly explain why these results are labeled “Fold 0” in the figure. The gradients here are with respect to layer activations (gradients with respect to parameters behave similarly). The network weights are initialized with the standard 

To show that convergence to a suboptimal solution here doesn’t have anything to do with the size of the gradient norms per se, I will now introduce a manipulation that will increase the gradient norms, but will worsen the performance. Here it is (in blue):

So, what did I do? I simply changed the initialization in a pretty minimal way. Each initial weight matrix in the original networks is a 

So, I introduced a manipulation that increased the size of the gradient norms overall, yet the performance got significantly worse. Conversely, I will now introduce another manipulation that will shrink the size of the gradient norms, yet will improve performance substantially. Here it is (in green):

As you may have guessed from the label, this new manipulation initializes the weight matrices to be orthogonal. Let’s recall that orthogonal matrices are the least degenerate matrices among matrices of a fixed (Frobenius) norm, where degeneracy can be measured in different ways, for example, as the fraction of singular values smaller than a given constant. Here’s how the gradients look after the first few epochs in this case:

In fact, I can even multiply the initial orthogonal matrices by some factor smaller than 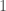
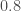

There’s another, slightly subtler, reason for why the size of the gradient norms can’t explain the bulk of the training difficulties with deep neural networks: modern adaptive SGD variants typically used in practice these days, such as Adam, apply updates that are approximately invariant to the size of the gradient norms. So, if the only problem with training deep networks were a simple scaling problem, these methods would have easily dealt with that issue.
So, what’s going on? If the size of the gradient norms per se isn’t responsible for training difficulties, then what is? The answer is that it’s the degeneracy of the model that, by and large, determines the training performance. Why is degeneracy harmful for training performance? Intuitively, the reason is that learning slows down substantially along degenerate directions in the parameter space, hence degeneracies reduce the effective dimensionality of the model. So, you might think that you’re fitting a model with 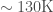
This reduction in the effective degrees of freedom can be quite substantial, as in the

As depth increases, the singular values of the product matrix become increasingly concentrated around 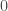
A nice visualization of this degeneration process is presented in a paper by Duvenaud et al. (2014):
 As depth increases, the input space (shown on the top left) gets distorted into increasingly thin filaments with only a single direction (orthogonal to the filament) at each point in the input space affecting the network’s response (it may be a bit hard to extrapolate from this figure how input spaces of more than two dimensions will behave under a similar mapping, but it turns out they become “hyper-pancakey” locally, i.e. there is a single direction at each point, orthogonal to the pancake surface, the network is sensitive to). Along that sensitive direction, the network in fact becomes hyper-sensitive to variations.
As depth increases, the input space (shown on the top left) gets distorted into increasingly thin filaments with only a single direction (orthogonal to the filament) at each point in the input space affecting the network’s response (it may be a bit hard to extrapolate from this figure how input spaces of more than two dimensions will behave under a similar mapping, but it turns out they become “hyper-pancakey” locally, i.e. there is a single direction at each point, orthogonal to the pancake surface, the network is sensitive to). Along that sensitive direction, the network in fact becomes hyper-sensitive to variations.
Finally, I can’t resist mentioning my own paper (with Xaq Pitkow) at this point. In this paper, through a series of experiments, we argue that the degeneracy problem I discussed in this post severely afflicts training in deep nonlinear networks, and that one of the ways (and quite possibly the single most important way) in which skip connections help training in deep networks is through breaking such degeneracies. I suspect that other methods like batch normalization or layer normalization that also help training in deep networks also work at least partly through a similar degeneracy-breaking mechanism, in addition to any other potentially independent mechanisms such as reducing the internal covariate shift as originally proposed. It is well-known, for example, that divisive normalization is an effective way of decorrelating the responses of hidden units, which in turn can be seen as a degeneracy-breaking mechanism.
Update (1/5/18): I should also mention this important recent paper by Pennington, Schoenholz & Ganguli. Orthogonal initialization completely eliminates degeneracies in linear networks, but not in nonlinear networks. In this paper, they provide a method to calculate the entire singular value distribution of the Jacobian of a nonlinear network and show that a depth-independent, non-degenerate singular value distribution can be achieved, with careful initialization, in networks with hard-tanh nonlinearities, but not in ReLU networks. The empirical results show that networks with depth-independent, non-degenerate singular value distributions train orders of magnitude faster than networks whose singular value distributions become wider (higher variance) and more degenerate with depth. This is a powerful demonstration of the importance of eliminating degeneracies and controlling the entire singular value distribution of a network, not just its mean.

[…] are as bad as zero singular values: they both restrict the effective capacity of the model (see this previous post for a discussion of this […]
[…] of recurrent neural networks (RNNs) suffers from the same kind of degeneracy problem faced by deep feedforward networks. In fact, the degeneracy problem is likely compounded in RNNs, […]