One of the fundamental challenges facing the brain is a trade-off between what we might loosely call learning and memory. On the one hand, we want our synapses to be highly plastic so that we can learn from our experiences quickly. On the other hand, we want our memories to be stable so that they are not easily overwritten by the constant barrage of experiences that we face every day and this seems to require rigid synapses. So, what is the optimal way to strike the balance between these two conflicting requirements?
Building on a series of previous papers, Benna & Fusi (2016) address this question in the context of a highly simplified model of synaptic modifications. In this model, the current value of a synapse is assumed to be a linear superposition of all the past modifications made to that synapse, weighted by a function of the time since that modification:

Here 

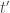
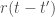


To formalize the plasticity-rigidity trade-off, they define a signal-to-noise ratio that quantifies how well we can decode a past synaptic modification event from the current values of the synapses. The signal is defined as the mean overlap between the current values of the synapses and the past synaptic modification pattern:

and the noise is defined as the standard deviation of this overlap:

where the angle brackets denote averages over the stochastic modifications. With the assumptions made, it is then straightforward to derive that the signal-to-noise ratio for a memory inducted at time
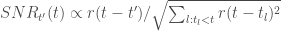
Heuristically, we can see from this equation that the slowest decaying 
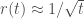

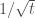
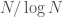
The rest of the paper is devoted to coming up with a hand-crafted, tractable dynamical system (which can be interpreted as describing the internal dynamics of a complex synapse model) that would display the desired

where 

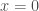

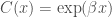




Although I find this model informative for elucidating the kinds of mechanisms required for achieving extensive memory capacity in an efficient way under the studied scenario (e.g. multiple variables with exponentially differing time-scales interacting with each other), I have two basic issues with the paper. First, the assumptions and simplifications they make to render the problem tractable also make it somewhat uninteresting from a practical viewpoint: uncorrelated events arriving at uncorrelated synapses is not a very practically relevant scenario. In the studied scenario, there’s also no accounting of the importance of a synapse for prior experiences (cf. Kirkpatrick et al., 2017). Incidentally, Kirkpatrick et al. (2017) show that any synapse that optimizes their elastic weight consolidation objective (which combines the loss in the current episode and deviation from the current value of the synapse weighted by the importance of that synapse for prior episodes) automatically satisfies the optimal
Secondly, the desire to come up with a tractable model also restricts the authors to a linear model (i.e the heat equation). But, there is no reason synapses should be linear. Nonlinear models might, in fact, perform better. There’s not much room for improvement over the linear model proposed in the paper, since both the 
So, an alternative approach would be to model the synapse as a nonlinear dynamical system (i.e. an RNN), and optimize its parameters (one can think of more sophisticated variations on this idea to learn more interpretable solutions) under more realistic scenarios. I find this approach very useful, because (i) the hand-crafted solutions we humans come up with usually tend to be highly special (e.g. an attractor with all eigenvalues equal to
